
Solving Maze using Reinforcement Learning
May 24, 2025
About:
Using q-learning to learn how to solve a maze. q-learning (quality learning) is a reinforcement learning algorithm which is useful for cases where we have a fixed number of possible positions and a fixed number of steps to take from each possible position. What happens in simple terms is the following-
We start at the starting position in the grid, and gradually take decisions according to the q-table, which stores the best decision known thus far from each position. As we make a decision, we get feedback about how good that decision was (it was a bad decision if its taking us to an obstructed position or out of the grid). Using this information we update the q-table at each step according to an equation (Bellman equation). We stop when we reach the goal/endpoint of the maze. As one can understand, the first time it would take a lot of time to reach the goal, as it is basically to be stumbled upon by chance. But gradually, the learnings start paying off, and the iterations complete faster.
Example:
In the below two examples, we see the model’s performance on the same maze at timepoints 100-110 in the top figure, and timepoints 990-1000 in the below figure. It pretty evident how the model has improved between these time points.
Learning at timepoints 100-110:
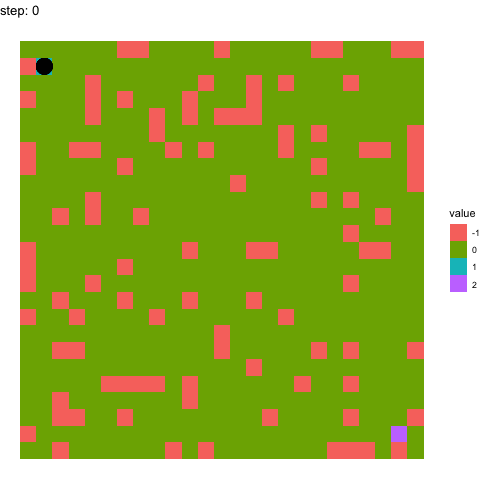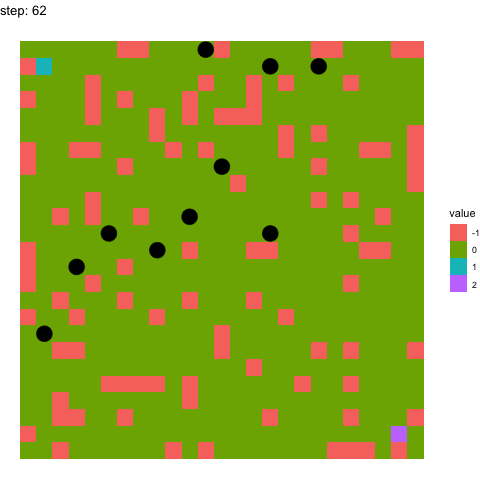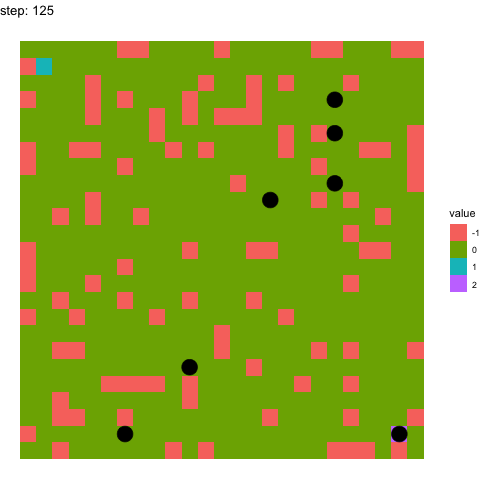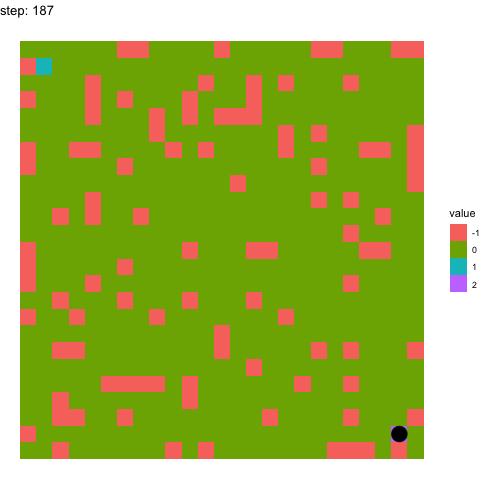
Learning at timepoint 990-1000:
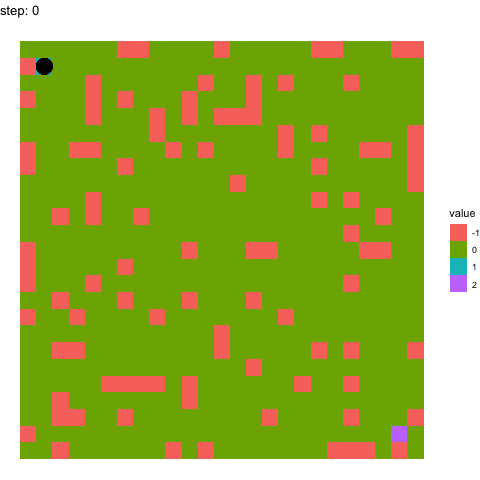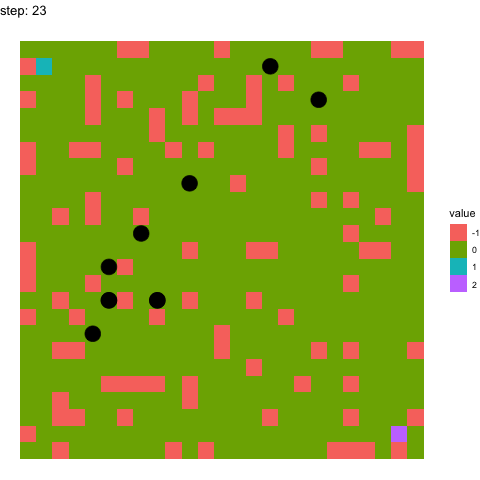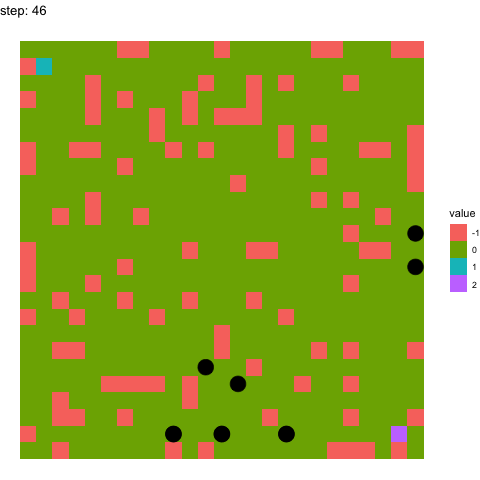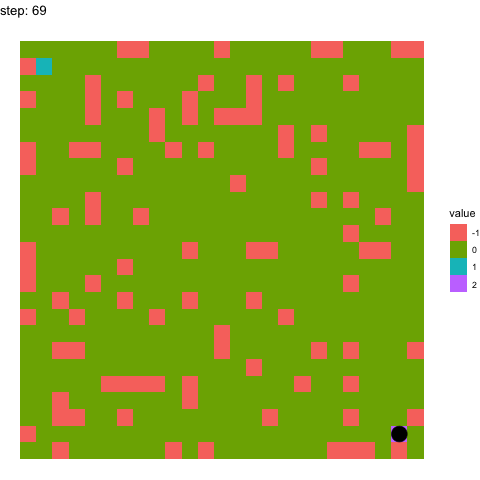
If you have any questions whatsoever, please feel free to email me or raise an issue on the repo. I would love to explain my implementation and assumptions made in detail!
Links:
- github link to project: https://github.com/shashkat/Maze-Solver-With-Reinforcement-Learning
- Adapted q-learning algo code from this youtube tutorial: https://youtu.be/qTY4Rr-x5q0?si=LbdH3lRjo3Otrk-s